


What ChatGPT applications can learn from self-driving?
How to build AI and not go bankrupt.


If you were not living under a rock, you already know ChatGPT was a key technology story of 2023. ChatGPT is appealing due to its generality and seemingly unlimited potential to automate work. Goldman Sachs estimates more than 300 million jobs could be automated around the world. Now, the question that every entrepreneur and VC is asking is: how do you actually build useful products and defensible businesses from it? What kind of products are now possible? Who will the winners and losers be and why?
When asking these questions it’s useful to look at another recent AI story: self-driving. In the past decade, many companies pursued and died on the way to build self-driving. Others, such as Waymo and Cruise were more fortunate and with billions of $ and a decade of R&D now offer fully driverless commercial deployments in large cities. Are ChatGPT applications going to follow a similar trend?
For the last 12 years, I have been working at the intersection of AI and business. First in research, doing a Ph.D. in Robotics at Oxford. Later in the industry, starting two startups in the space. Finally, in corporations, leading large self-driving efforts at Lyft Level 5 and Toyota. I have been fortunate to see both the technology and business aspects of these endeavors closely. I believe there is much to learn from self-driving as a lens to peek into what might lie ahead in AI.
Generality vs. Robustness vs. Value
The value of AI comes from the opportunity to automate today’s work or do new work. The more you automate, the more value you can generate for the end user.
Making things technically possible, however, is a whole different story. When building an AI product its good to think about two aspects:
Generality - how constrained or open-ended is task at hand? A system that needs to handle a wide range of situations needs to be much more capable than one that only needs to handle a narrow scope.
Robustness - does the system need to work perfectly (compared to humans) to generate value? A system can work fine in 99% of the cases and produce incorrect results in 1% of them. Is this case acceptable for the product to be used?
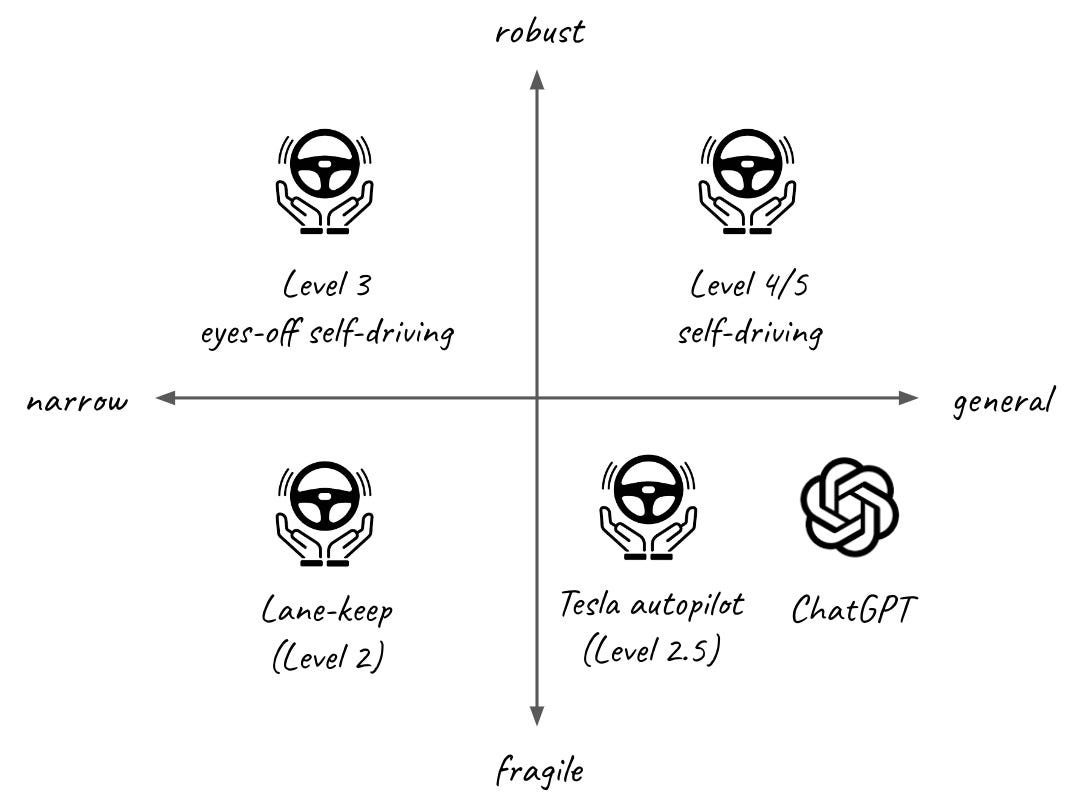
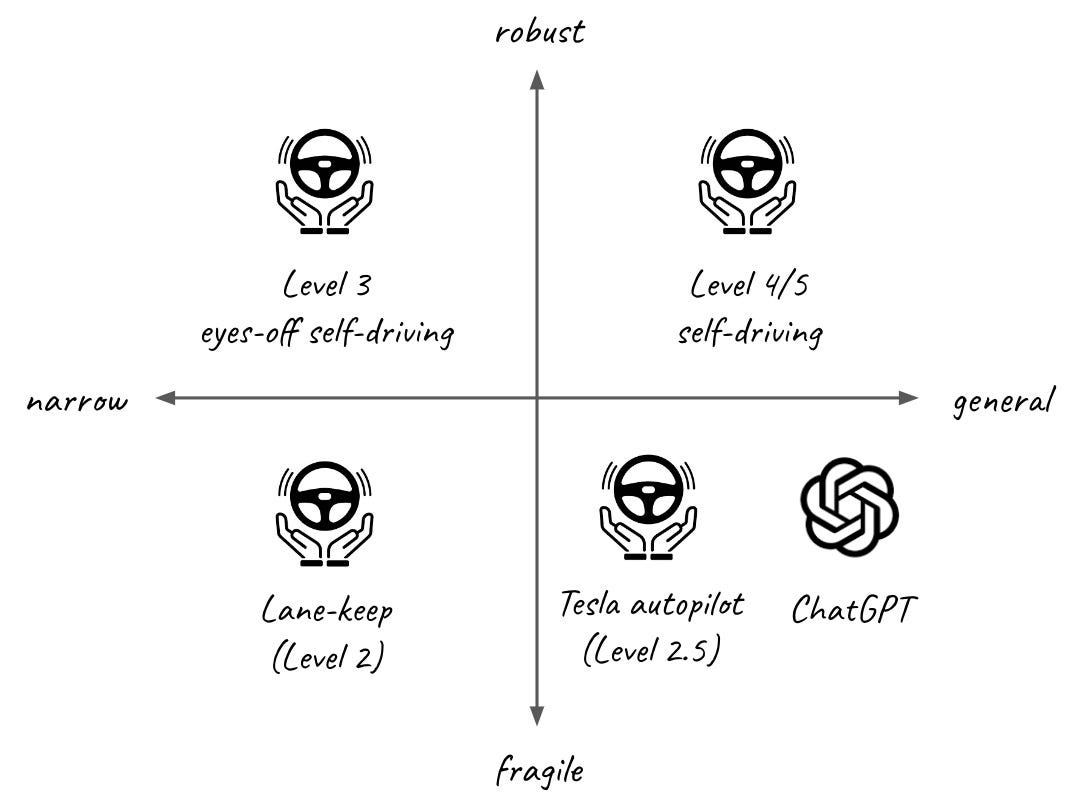
Why is this classification important? As it turns out, it has dramatic implications on what is technologically possible and managing user expectations. To recognise this, self-driving industry devised its own closely-matching categorisation system:
Level 1/2 (lane-keep assistant) - is narrow and fragile delivering partial automation on highways but where the user needs to keep paying attention at all times.
Level 2.5 (Tesla Autopilot) - is general and able to handle a wide range of city situations but is fragile requiring users to still keep paying attention at all times.
Level 3 (BMW G70 autopilot) - is narrow and constrained to handling slow-moving traffic jams on highways but robust, not requiring users to pay attention.
Level 4/5 (Cruise and Waymo robotaxis) - is both general and robust, able to handle a wide variety of situations without user input.
As you see, different levels of self-driving have different levels of capability and different costs to develop.
Similarly, you can put almost any AI application somewhere in this graph. Where does ChatGPT sit? As you probably guessed, ChatGPT and most applications built on top fall into the general fragile / narrow fragile quarters. They can do impressive things but their output still needs to be reviewed to be usable.
What does this mean if you are trying to build an AI company nowadays? What should you actually aim to build? Let’s look into history for insights.
Learning 1: Narrow fragile applications can be built reasonably quickly.
The self-driving boom of 2014-2018 was also powered by a breakthrough in technology. In particular LIDAR sensors and supervised deep learning. LIDAR allowed machines to see in 3D. Deep learning allowed to label a lot of data and turn it into powerful perception systems. The remaining building blocks (such as simultaneous localisation and mapping - SLAM systems and trajectory planners) were available, albeit in crude form, from the research community. All it took was a small team able to put all of it together.
Many companies including Cruise, NuTonomy, Zoox, Nuro, Aurora, Voyage, PonyAI, FiveAI, Drive.AI, Oxbotica, aiMotive took this opportunity and quickly gained investor traction raising 10s-100ds millions of $ with their demos. These showcased prototypes of automated lidar-equipped vehicles operating in constrained environments, usually in parking lots or on pre-mapped roads and under human supervision. Although often magical to investors, the demos were too fragile for any real-world use because things went wrong all the time (as any robotics practitioner would be able to attest).
In parallel, the advent of ChatGPT is now being followed by a wide variety of various demos and some massive investments. On one end, you can find recommendation systems, such as Github Copilot or Jasper where the user is still in charge and can correct the system’s output. On the other end, people are playing with autonomous applications, AutoGPT and chain-of-the-thought prompting that are able to autonomously achieve seemingly any task. If you though played with any of them on your own you will agree that they often need corrections and, as such, are not yet suitable for practical applications that demand reliability.
Learning 2: To improve one needs in-domain data from a deployed system.
The key challenge in building reliable AI systems is to overcome the robustness and generality gap. A self-driving vehicle must be able to handle a wide variety of situations and handle each of them robustly 100% of the time. When lives are at stake, 99% is simply not good enough. Many possible applications of GPT also have this property. You can’t have a doctor chatbot that outputs wrong instructions 5% of the time or an automated payment accountant that sends money to the wrong account.
The way all self-driving programs approach improvement is through continuous deployment, testing, and improvement. A version of the system is deployed to a testing fleet that is supervised by a safety driver who can take control of the vehicle at any moment. This can be due to mistakes in perception, planning, or localization systems. Each such ‘disengagement’ event is then analyzed and added to the training/testing set that is used to develop subsequent iterations of the vehicle’s systems. This cycle continues, often for years, until the performance is acceptable to remove the safety drivers.
Similarly, OpenAI is using collected data to improve its chatbot to be more accurate and better at solving specific problems. This is required despite training on almost all open data on the internet. The datasets about specific ways people use ChatGPT and their responses to its output simply don’t exist. The only way to get it is from an already deployed system.
Learning 3: Startups pursuing general-robust applications usually die.
Running an in-house cycle of continuous deployment, testing, and improvement can be very expensive. It costs roughly several billions of $ to reach Level 4/5. This is something few can afford.
Many people tried to decrease reliance on real-world road testing through simulation. This is useful and more cost-effective but it doesn’t really substitute the need for extensive road-testing. It is simply too hard to discover and simulate the long tail of rare events that happen on the road, and the reaction of the vehicle and other traffic participants to it.
As a consequence, most of the startups pursuing general on-road autonomy have not survived. They have typically been acquired for talent by larger players, such as, Cruise, Zoox, NuTonomy or Voyage. Even well-funded efforts backed by Uber, Lyft, or Ford went through corporate transitions. Eventually, the market will only support a few players with deep pockets i.e. Google or GM, which can pick up the check.
A different approach is instead to focus on shipping a narrow-fragile product first and expand from there. Instead of buying the usage data, the aim is to gather it organically for free through product usage. It might be a longer way but is certainly more cost-friendly.
This is what Tesla is doing. Tesla autopilot first featured lane-keep assistance on highways only and used the data its fleet collected to gradually expand the generality and performance of autopilot over time. While not yet robust enough, the system is still significantly capable.
Implications for building ChatGPT applications
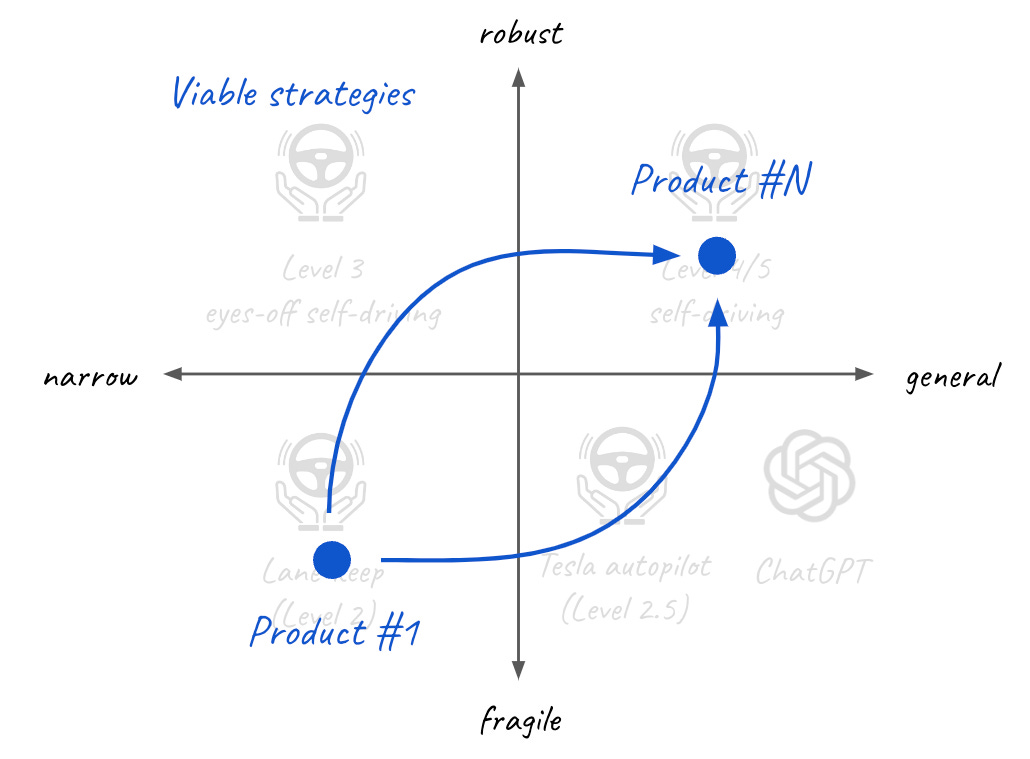
What are the learnings from all of this if you are building a ChatGPT application? I think there are several:
Don’t try to build something that replaces humans - Replacing humans is too difficult due to the long tail of events and robustness required. It can be achieved if you have a lot of time and $ but is not a good prerequisite for shipping a product.
Narrow the application domain and ship a human assistant that delivers value on day 1 - Narrow fragile applications can be built quickly and various assistants or copilots already proved to be valuable in several domains. The key is that humans are always eventually in charge of output, can review it, and take responsibility. This is in exchange for the task requiring less effort or time.
Collect all the data and human corrections - This allows you to gather a dataset allowing you to improve the performance of the product. With every user interaction, you will be able to make your system work a little bit better. It allows you to both broaden and deepen the model’s specialisation in your domain. As a result, this proprietary dataset will eventually create a defensibility moat separating the performance of your product from any of the new players.
Iteratively ship improvements to your system to increase generality and robustness - The collected dataset allows you to see how the system is used and fine-tune it for these use cases. In turn, a better model can be delivered back to users. In particular, increasing generality will expand the addressable market while increased robustness will require less interaction or perhaps, not requiring any supervision at all increasing customer ROI.
What are your thoughts and experiences with building GPT applications? Let me know in the comment below.
Credits: Thanks to Nathan Benaich, Toby Coppel and Ashesh Jain for pre-read and comments.
Great insights and thought provoking analogy, and fully agree on an advice on keeping humans in the loop and acquiring data. My observations is that while 2D quadrant plot is nice and insightful, it misses many more axes, for one, reward. There is a huge reward for going robust/general in self driving not so much with LLMs, thanks to the non-time-critical/asynchronous nature of decision making in LLMs (no one minds reviewing, say, reversible ticket buying agent decisions 3 times in a day and correcting it, reviewing self-driving irreversable decisions are not so appealing).