


What team do you need for your ML project?
How to build AI A-Team from scratch.


Everyone now seems to be doing AI. Big companies do it. Small startups do it. People of all backgrounds tinker with it in the evenings. This begs the question: who do you actually need to build ML projects today?
Often, when building AI applications, it’s enough to take any existing off-the-shelf ML component and use it. Be it an image classifier, LLM API, or diffusion image generator. You plug it together with whatever data pipeline or UI is suitable, ship it, and you are done. No ML skills are needed.
Sometimes, reusing existing things is not enough. You may be building something that has never been done before, or require performance not available in what exists, or use specific new datasets. For example, you could be trying to use ML to discover drugs, make cars drive themselves, or create the next GPT5. What should you do in such situations? Who should you hire? What should they do, and how?
I was fortunate enough to build several AI R&D teams across both startups and large corporate efforts. Starting a new ML project and hiring a team is tricky, akin to building an NBA team. There are patterns though that can help you identify the right people. Let’s first dive deeper into what ML actually does and how to measure its progress before you understand who to hire.
How Machine Learning differs from Software development
If you are a programmer building typical software, i.e. websites, games, or mobile apps, the components you use are reasonably well understood. You know how computers work, how to program them, and what to expect. You know what a database is, how backend APIs work, or how UI is rendered in the front end. Over the past few decades, all these components have been used and recombined in many ways across the industry. When starting a new project, it is possible to break it down into these pieces and plan execution. Things can still go sideways, and projects run over, but it rarely happens that it would not work at all.
This is not the case when building a brand-new ML project. If something was not done before, it’s impossible to tell with certainty how well it will work. Or whether it will work at all. What kind and how much data is necessary? What is the best neural network architecture and training procedure? Often, it’s not even clear how to measure success!
Questions like this can make seasoned engineers, managers, and product managers nervous. If success is not guaranteed, nor is the timeline or costs known, how should one manage the project? The return on investment?
The hard truth is that the only way to find answers to these questions is by trying. This requires experimentation, and the entire machine learning workflow revolves around it. Experimentation is the way an ML team achieves its results.
Experimentation loop = the engine of the ML team
Training and evaluating an ML model is called an experiment. It answers a simple yes / no question called hypothesis. Usually, in the form of whether a particular training combination works better than the best one found so far. This then results in an improved system, learnings are gathered, and the process repeats. Eventually, if the performance is good enough, the product can ship to customers.
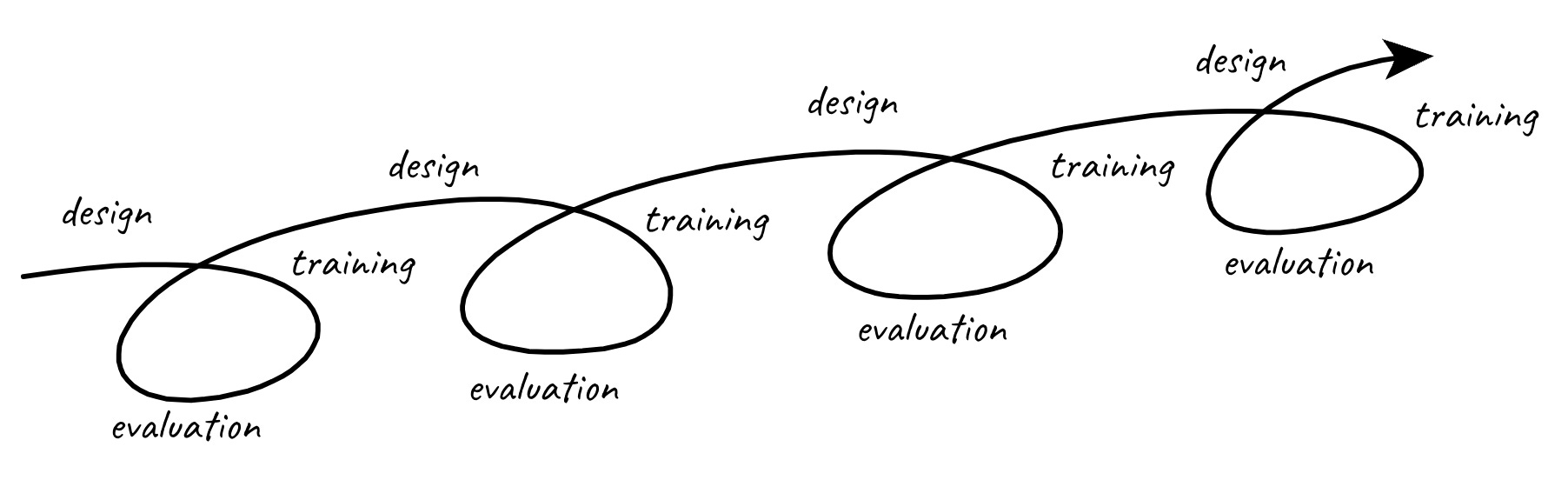
Sometimes, it’s enough to do only a few experiments to achieve good results. Often, it’s much more. Building projects of high ambiguity or requiring high performance can take hundreds of experiments. For example, building a perception and planning system for a self-driving car takes years of continuous refinement of both model, training, and evaluation sets.
There are also times when, no matter how many experiments you do, the results are just out of reach. The required performance might be unattainable with available resources or the state of technology available. That’s OK, and a result like that should also be celebrated and found out as quickly as possible to save resources.
Given the central roles of experiments, it is worth understanding what makes a good experiment vs a bad one.
First of all, a well-designed conclusive experiment contributes to progress much more profoundly than several inconclusive ones. A good experiment verifies what works or shows what should be avoided to move forward. A bad experiment does not make you any smarter and keeps you in the same place.
The speed of executing experiments also matters. The same experiment can be done in a day, a week, or a month. The faster the experiments can be executed the more progress can be made in the same period. The same is true for cost. If running experiments is cheap, many can be done in parallel. On the other hand, one can usually afford only a few expensive ones. For example, training ChatGPT from scratch takes months.
As a result, you can measure the velocity of an ML team in terms of the quality of experiments and speed of executing them:

Maximising the velocity is the main way the ML team accelerates its way to results. Each new member can be hired and evaluated based on how they contribute to the team's velocity.
Researchers vs Engineers
The velocity formula above naturally leads to two main skills you can look for when hiring people:
Ability to design good experiments and
Engineering required to execute them.
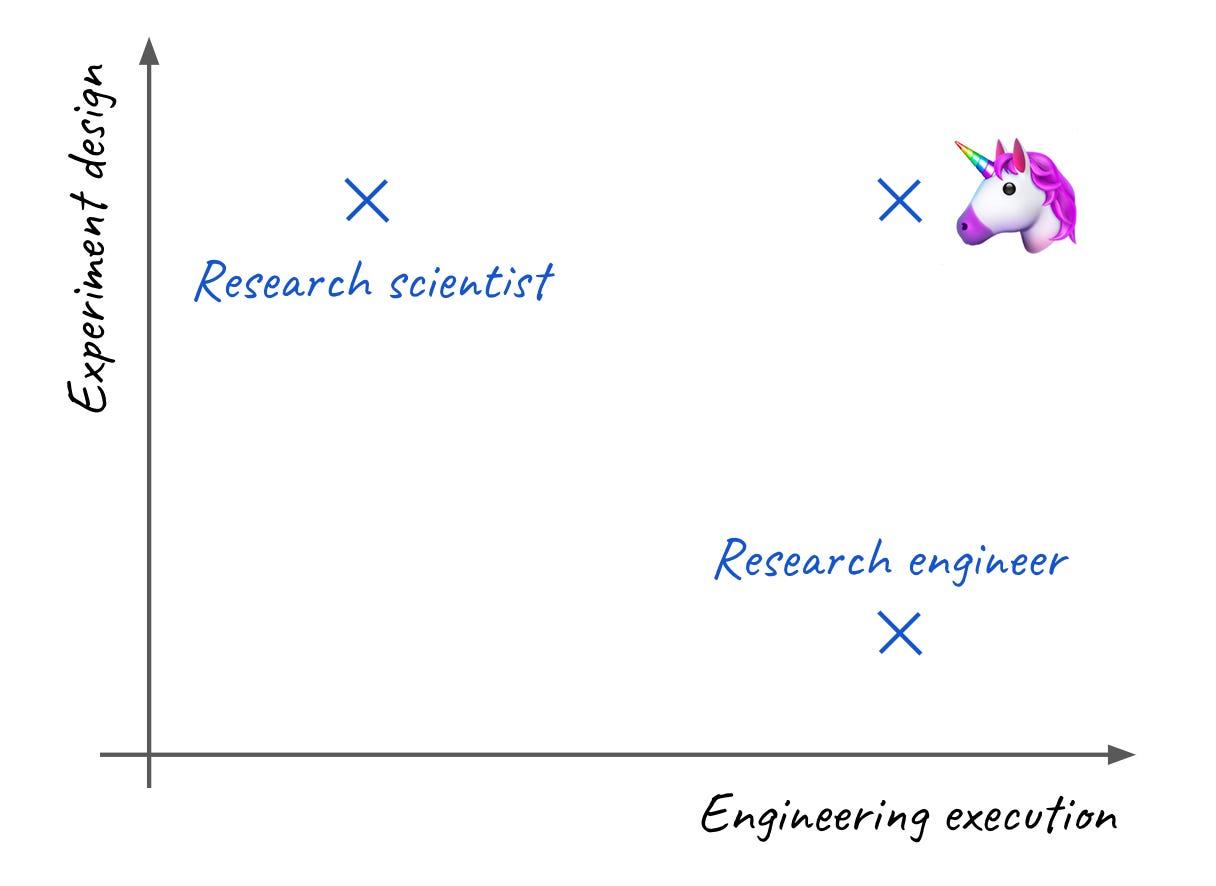
Sometimes, you find a unicorn - someone who is great at both. Such people exist but are exceedingly rare. It’s not the best strategy to hope you will build your entire team with them.
Most people are stronger in one area than in the other. This leads to two main roles found in ML teams:
Researchers usually have professional training, a Ph.D. that helps them to investigate the relevant state of the art, design experiments, and scrutinise the results. On the flip side, their engineering skills are often limited, which comes at a cost in large-scale endeavours or team efforts.
Research engineers, on the other hand, are usually much stronger in engineering and can write high-quality code. They should have experience with ML libraries and frameworks (i.e. PyTorch, TensorFlow, W&B..) and can use them to write high-performance training pipelines or prepare datasets. They might not design experiments themselves but work with research scientists to execute them.
How many of each do you need? It depends, but a good start is to have one or two of each to start the project. With them, you can get going. Once the baseline of the system exists, it opens avenues for more people to join the effort. They can carry out more experiments or accelerate their scale and execution. The velocity formula should be your guide in who you need at each point of the endeavour.
Identifying the roles you need and what they will do is only the first part of the story. You will still need to find, interview, and convince people to join your company. This is hard, especially today. Let’s cover that in another post!